
After winning Miss Buenos Aires, she went viral on Latino social media.
Read More
First released in 2006, the PlayStation 3 has several video game titles that have stunning graphics even today.
Read More
Sometimes, simple words can have the most profound meaning.
Read More
John Wayne movies have stood the test of time and continue to delight audiences of all ages.
Read More
While you are suffering from constipation, you may wonder what helps with constipation. Here are 10 tips and 9 foods to eat that may relieve constipation.
Read More
Our basic biscotti recipe will help you to make this classic Italian delight right on your own kitchen.
Read More
Taylor Swift's beauty tips and skincare routine underline the importance of consistency, hydration, and nutrition.
Read More
These quotes about helping others will inspire you to give a hand to other who need.
Read More
The online bullying was started in December last year.
Read More
Feeling alone quotes serve as reminders that we're never truly alone in our experiences.
Read More
This quote gently reminds us that beauty is not just a reflection in the mirror.
Read More
From these meaningful quotes about smiling, we can learn just how powerful a simple gesture like smiling to ourlseves and our surrounding.
Read More
Liverpool FC has made an approach for the 45-year-old Dutch manager.
Read More
The horses were frightened due to loud noises from nearby construction work.
Read More
Shropshire has various romantic and picturesque spots for couples to enjoy together.
Read More
This rule was made to protects travelers during the flight.
Read More
Peter Pan's quotes capture the essence of childhood, friendship, and courage.
Read More
The platform was threatened with a ban after allegations of espionage and Chinese government involvement.
Read More
Amid drama and sadness, the story contains many quotes.
Read More
Kylie and Timothée haven't said anything about it.
Read More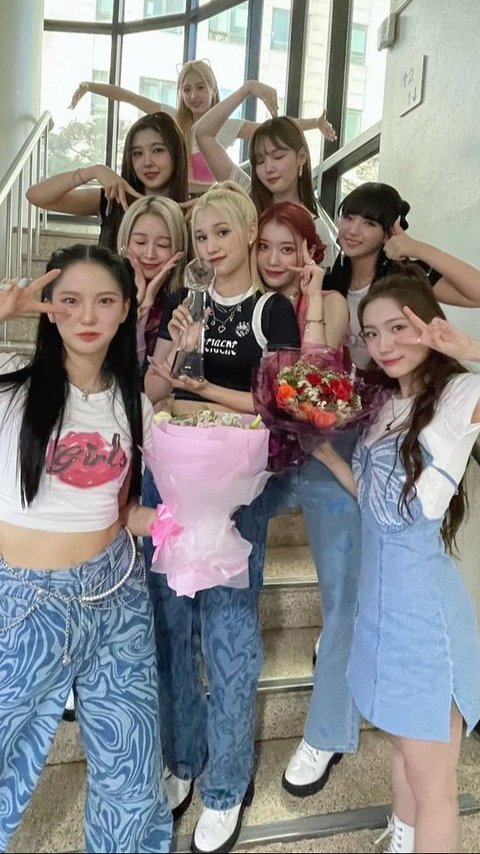
Their contract was supposed to last two years and six months.
Read More
This special event was attended by a series of popular K-Pop idols.
Read More
Do you ever hear words that make you feel small or sad? Some are mean and hurtful
Read More
The fine was levied against festival organizers following the singer's headline set.
Read More
K-pop girl group NewJeans reportedly plans to release a new music project next month.
Read More